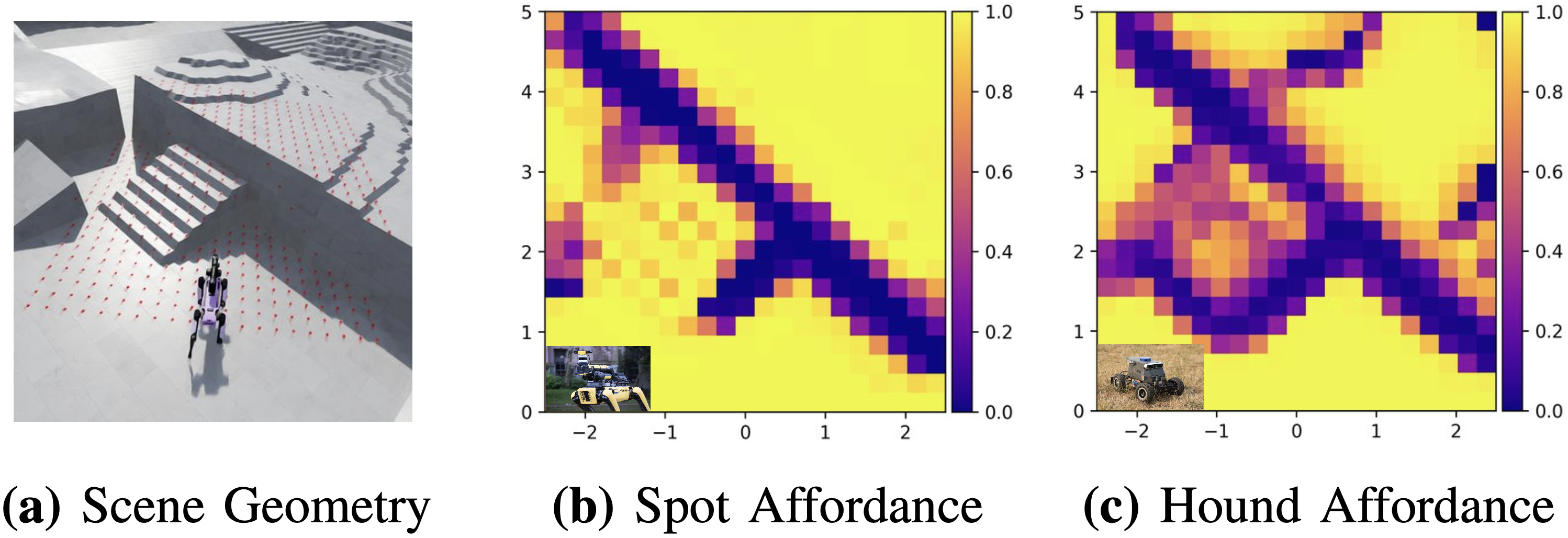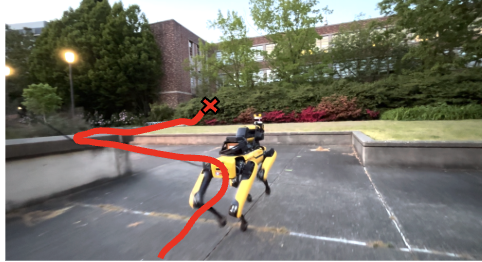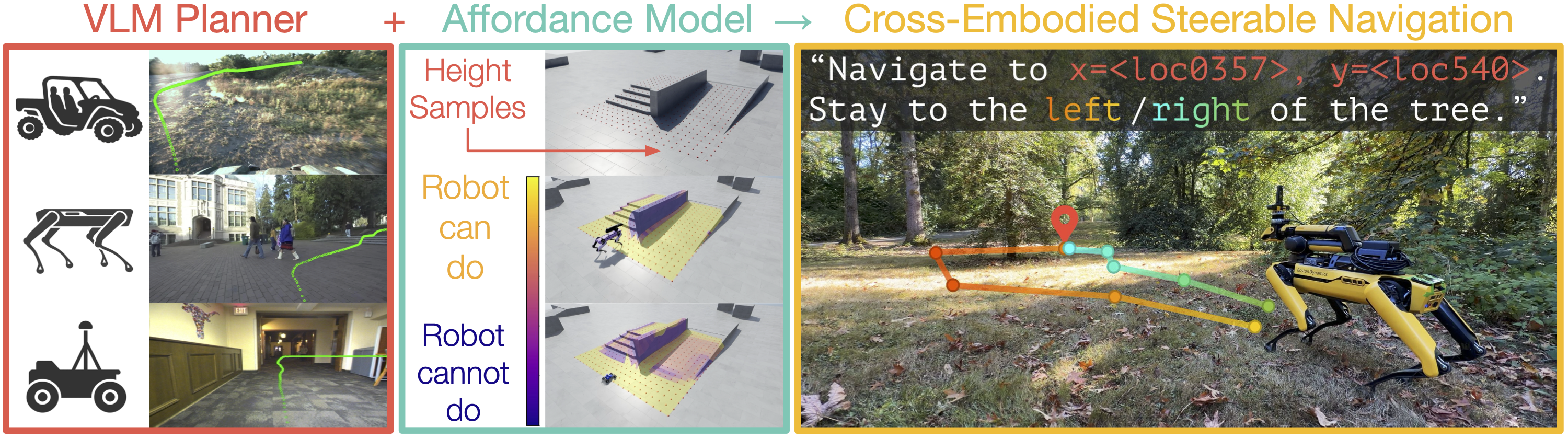
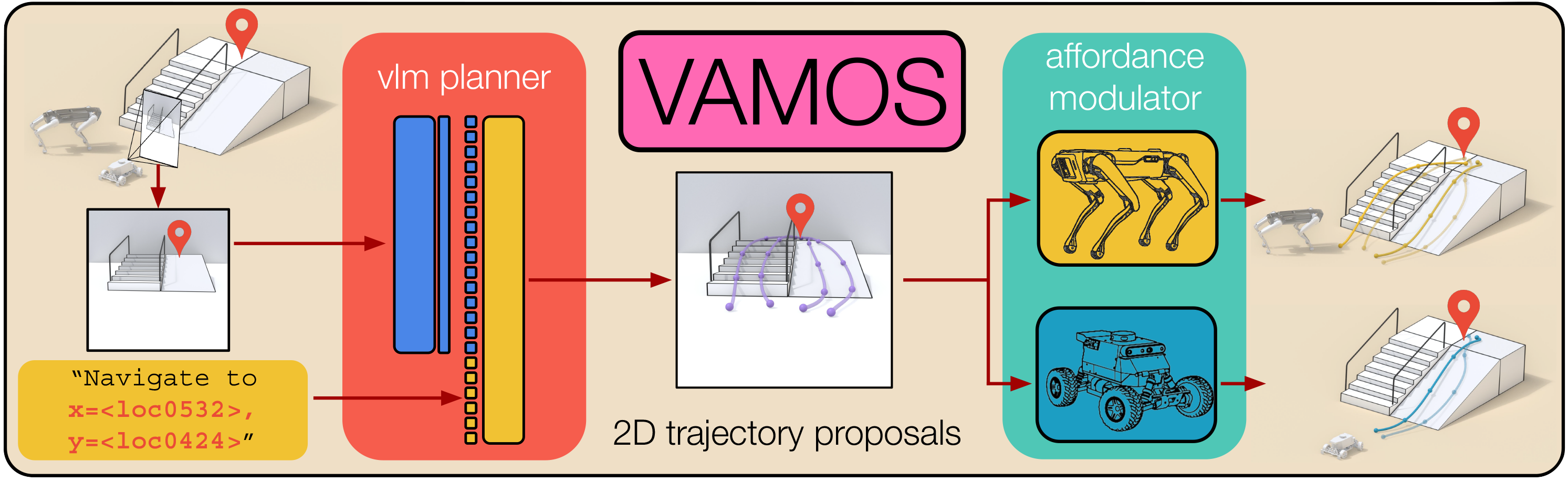
A fundamental challenge in robot navigation lies in learning policies that generalize across diverse environments while conforming to the unique physical constraints of specific embodiments. Quadrupeds can walk up stairs, wheeled robots cannot.
VAMOS addresses this challenge through a carefully designed hierarchical architecture that separates concerns:
- High-level VLM Planner: Learns from diverse, open-world data to understand semantic navigation
- Per-embodiment Affordance Model: Learns robot's physical constraints safely in simulation